エクセルはデータ解析・管理を行うツールとして非常に機能が高く、上手く使いこなせると業務を大幅に効率化できるため、その扱いに慣れておくといいです。
ただ機能が充実しているあまり初心者にとっては処理方法がよくわからないことも多いといえます。
例えば文字列から日付を抽出する方法について理解していますか。
ここではエクセルにて文字列(文章)から日付を抽出する方法について解説していきます。
エクセルにて文字列(文章)から日付を抽出する方法【和暦】
それでは、下記の日付を記載したメモデータを使用しエクセルにて文字列から日付を抽出する方法について確認していきます。

文字列から日付を抽出するには「IFERROR関数」と「FIND関数」と「MID関数」を使用します。
「MID関数」で文字列から指定した文字数範囲の抽出を行い、この文字数範囲の指定に「IFERROR関数」と「FIND関数」を使用するわけです。
今回の例文のように文章の途中に日付がある場合には、「元号の種類(令和、平成、昭和)」「文字抽出を開始する先頭からの文字数」「抽出する文字の長さ」が各文章で異なる場合がありますが、上の方法であれば柔軟に対応可能です。
それぞれの関数で何をしているのかを示したのが下のイメージです。
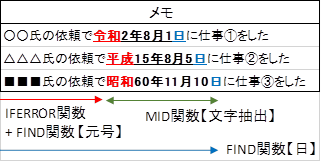
まずIFERROR関数とFIND関数で先頭から「元号(令和、平成、昭和)」までの文字数を算出します。
IFERROR関数の説明も兼ねて、まずは「令和」と「平成」までの文字数の算出例を紹介します。
と入力します。
まずFIND関数の「FIND(“令和”,B8)」の部分は【B3】対象文字列(セル)で文章中の【”令和”】までの文字数を算出する
という意味です。
次にIFERROR関数は、「前半の数式がエラーの時には、後半の数式結果を表示する」関数です。
今回の場合は、
前半の数式を満たさない(文章中に令和がない)場合には
後半:文章中の【”平成”】までの文字数を算出する。
という意味になります。

これで各文章の先頭から「令和」または「平成」までの文字数が算出できました。
同様にこの数式に「昭和」までの文字数を算出する条件を加えると次のようになります。
=IFERROR(FIND(“令和”,B3),IFERROR(FIND(“平成”,B3),FIND(“昭和”,B3)))
と入力します。
先ほど入力した数式の後半部分に再度「IFERROR関数」を入力することで
「昭和までの文字数」を算出する条件を追加することができます。

これで元号(令和、平成、昭和)までの文字数が算出できました。
次にFIND関数で先頭から「日」までの文字数を算出します。
と入力します。
【B3】対象文字列(セル)で文章中の【”日”】までの文字数を算出する
という意味です。
最後に+1とすることで、この後の抽出結果に「日」が含まれるようにしています。

これで各文章の先頭から「日」までの文字数が算出できました。
最後にMID関数で文章中の日付部分だけを抽出します。
ここでは数式の分かりやすさを優先して、セル番号で入力します。
と入力します。

【C3】「元号」から【D3-C3】「日」までの文字数-「元号」までの文字数(すなわち、「元号1文字目」~「日」まで)
の範囲を抽出する
という意味です。
これを他のセルにも適応すると下記の結果となります。

これで文字列から日付(和暦)を抽出することができました。
関数を直接記載した場合のコード
分かりやすくするために抽出過程の結果を残した形で表現しましたが、
文章の横のセルに抽出した日付のみを直接表示するには、以下を入力します。
=MID(B3,IFERROR(FIND(“令和”,B3),IFERROR(FIND(“平成”,B3),FIND(“昭和”,B3))),FIND(“日”,B3)+1
-IFERROR(FIND(“令和”,B3),IFERROR(FIND(“平成”,B3),FIND(“昭和”,B3))))
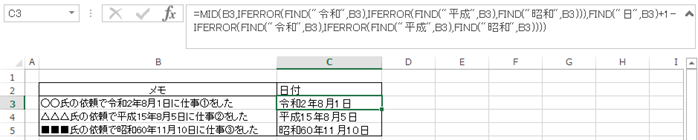
長文で分かりにくく感じると思いますが、前述の数式を直接入力したものです。
ちなみに、文章の先頭に日付がある場合には、以下を入力すれば日付のみ抽出が可能です。
=MID(B3,1,FIND(“日”,B3))

エクセルにて文字列(文章)から日付を抽出する方法【西暦】
上では文字列(文章)から和暦の抽出方法について記載しましたが、今度は西暦についても確認していきます。
先ほどデータを和暦から西暦に変更した下記データを使用します。

西暦であっても、日付表記が「年月日」であれば和暦のときと同じ数式で、文章から日付を抽出することができます。
まずは年数までの文字数を算出します。「199」または「20」となる文字列を検索条件とします。
と入力します。
今回の場合は、
前半の数式を満たさない(文章中に199がない)場合には
後半:文章中の【”20”】までの文字数を算出する。
という意味になります
ここで注意が必要なのは、前半部分で「199」を指定するということです。
もし「20」を前半で指定すると、IFERROR関数は前半部分の条件を先に検索するため日付中の「20日」からの文字数を算出してしまい、目的の日付抽出ができなくなります。
また「19」とすると同様に日付中の「19日」までを算出してしまいます。
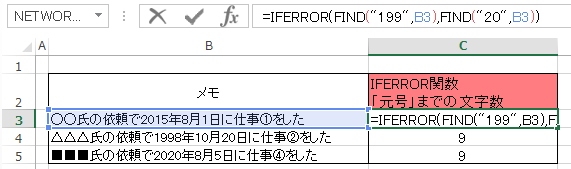
これで各文章の先頭から「西暦」までの文字数が算出できました。
和暦では「令和」「平成」「昭和」の3条件で算出しましたが、「1990年代」「2000年代」を抽出する場合はこれでOKです。(1980年代も混在している場合には和暦の時と同様に、3つめの条件を加えてください。)
次にFIND関数で先頭から「日」までの文字数を算出します。
=FIND(“日”,B3)+1
と入力します。

最後にMID関数で文章中の日付部分だけを抽出します。
ここでも数式の分かりやすさを優先して、セル番号で入力します。
=MID(B3,C3+1,D3-C3)
と入力します。

これで文字列(文章)から西暦日付を抽出することができました。
関数を直接記載した場合のコード
文章の横のセルに抽出した日付のみを直接表示するには、以下を入力します。
=MID(B3,IFERROR(FIND(“199”,B3),FIND(“20”,B3)),FIND(“日”,B3)+1
-IFERROR(FIND(“199”,B3),FIND(“20”,B3)))

まとめ エクセルにて文字列(文章)から日付を抽出する方法【和暦と西暦別】
ここでは、エクセルにて文字列(文章)から日付を抽出する方法を和暦と西暦別に解説しました。
日付などの抽出は基本的にかなり複雑になるので注意して関数を入れていくといいです。
エクセルでのさまざまな処理に慣れ、日々の業務に役立てていきましょう。
コメント